Introduction
Dependability is a measure of system properties such as availability, reliability, maintainability, safety, and in some cases other characteristics such as security. In short, dependability describes a set of fundamental system properties that deals with the ability of the system to deliver a service under specified conditions within a given time that can justifiably be trusted. A systematic approach to analyzing the concepts of dependability relies on three significant aspects: the attributes of, the threats to, and the means by which dependability is achieved or enhanced as shown in Figure 1.

Figure 1: Dependability based on IEC 6005
Source: HIMA Paul Hildebrandt GmbH
In this context, a system may lose its intended functionality because it fails to fulfill a given specification due to a threat. Threats may be caused by poor development, non-sufficient specifications, or a poor manufacturing process that can lead to a loss of function. Depending on their time of occurrence and effects on the system, threats are usually categorized in a wide variety of definitions and terms.

Figure 2: Threats to a systems in the context of dependability
Source: HIMA Paul Hildebrandt GmbH
Failures, faults, and errors are the most commonly used terms and will be the focus of this paper. Although we do not focus directly on other terms, it is important to mention further terms such as defects, mistakes, bugs, malfunctions, and upsets which are either used as synonyms or as explanatory terms in some literature references.
Against this background, this module gives the main definitions relating to the threat’s terminology, shows a generic concept including definitions in accordance with safety standards, and highlights a simple interpretation as well as examples. Furthermore, the module presents an overview of the various classifications of threats.
Note: Since the standards of Functional Safety usually group safety solutions in systems, subsystems, elements, and components, it is important to note that in the following the term “system” is used as a general term for reasons of simplicity. The presented concepts can certainly be applied to other parts of a system.
1 Terminology
There are different definitions for the terms fault, error, and failure which may lead to wide confusion. Often, the terms are used interchangeably. In some cases, they are even used as synonyms. Trying to harmonize the definitions of these terms over the various standards, application areas, and languages is one of the most important subject matters in dependability and Functional Safety theory.
This section first presents the theoretical background of the terminology according to safety standards.
Afterward, it discusses the different concepts briefly and gives a simplified representation with related examples based on the perspective of the IEC 61508 standard.
Finally, it introduces the relationship between the terms mentioned above.
1.1 Standards
The development of terminology in the area of safety-related systems has always been in the focus of many standards and technical specifications. In addition, terminology in Functional Safety theory is always intensely discussed by Functional Safety experts and researchers. In the following, possible definitions of the terms fault, error, and failure are introduced on the basis of standards. A brief summary is then given by deducing a simplified definition.
1.1.1 IEC 60050
In the standard IEC 60050, which primarily deals with terminology and definitions, the following definitions can be found:
A failure is the termination of the ability of an item to perform a required function.
NOTE 1: After failure, the item has a fault.
NOTE 2: A "failure" is an event, as distinguished from "fault," which is a state.
NOTE 3: This concept as defined does not apply to items consisting of software only.
A fault is the state of an item characterized by inability to perform a required function, excluding the inability during preventive maintenance or other planned actions, or due to lack of external resources.
NOTE 1: A fault is often the result of a failure of the item itself but may exist without prior failure.
NOTE 2: In English, the term "fault" is also used in the field of electric power systems with the meaning as given in 604-02-01; then, the corresponding term in French is "défaut."
An error is a discrepancy between the calculated, observed or measured value or condition and the true specified or theoretically correct value or condition.
NOTE 1: An error can be caused by a faulty item, e.g., a computing error made by faulty computer equipment.
NOTE 2: The French term "erreur" may also designate a mistake.
1.1.2 IEC 61508
In the standard IEC 61508 the following definitions are stated in part 4:
A fault is an abnormal condition that may cause a reduction in, or loss of, the capability of a functional unit to perform a required function [ISO/IEC 2382-14, 14-01-10].
NOTE: IEV 191-05-01 defines “fault” as a state characterized by the inability to perform a required function excluding the inability during preventative maintenance or other planned actions, or due to lack of external resources.
An error is discrepancy between a computed, observed or measured value or condition and the true, specified or theoretically correct value or condition [IEV 191-05-24, modified].
A failure is termination of the ability of a functional unit to provide a required function or operation of a functional unit in any way other than as required.
NOTE 1: This is based on IEV 191-04-01 with changes to include systematic failures due to, for example, deficiencies in specification or software.
NOTE 2: See Figure 4 for the relationship between faults and failures, both in the IEC 61508 series and IEC 60050-191.
NOTE 3: Performance of required functions necessarily excludes certain behaviour, and some functions may be specified in terms of behaviour to be avoided. The occurrence of such behaviour is a failure.
NOTE 4: Failures are either random (in hardware) or systematic (in hardware or software), see 3.6.5 and 3.6.6.

Figure 3: Comparing the definitions from IEC 60050 and IEC 61508
Source: HIMA Paul Hildebrandt GmbH
By comparing these definitions, we can summarize that there are mainly two similar perspectives that may have a slightly confusing effect:
- According to the standard IEC 60050, a failure occurs when an item is no longer able to perform one or more of its required functions. Failure is therefore the event that takes place when a required function is terminated. After a failure, the item will usually be in a failed state, and we say that it has a fault. A fault is hence a state of an item and may have its origin in a random failure event or in a deficiency related to the item, its location, or its application. An error is the origin of a fault because it is within the acceptable limits of deviation from the desired performance. This perspective is supported by Rausand in System Reliability Theory: Models, Statistical Methods, and Applications.
- The second perspective relies on the standard IEC 61508, which sees the fault at the beginning of the chain. A fault can become active by leading to an error. Under some circumstances, an error may lead to a failure.
Since the standard IEC 61508 is the umbrella standard for Functional Safety, the second perspective selected in this chapter will be refined in the following sections.

Figure 4: Perspective 1 based on IEC 60050
Source: HIMA Paul Hildebrandt GmbH

Figure 5: Perspective 2 based on IEC 61508
Source: HIMA Paul Hildebrandt GmbH
1.2 Simplified definitions
Based on the above conclusion, a fault is a defect within a system. It could be a software defect or a hardware defect.

Figure 6: Examples of faults, errors and failures
Source: HIMA Paul Hildebrandt GmbH
A hardware fault is a physical defect or a weakness in a system. The main cause of hardware faults is the aging process of the system or a poor design process.
Examples:
- Short between two wires
- Broken transistor
- "Stuck" memory bit
- Transmission fault in the data transfer
A software fault is a flaw or imperfection that occurs during the coding process. The main cause of a software fault is a mistake due to a misunderstanding of the requirements or simply a lack of competency in coding methodologies.
Examples:
- Use of wrong assignment operators
- Infinite program loop
An error is a deviation from the required operation of a system. A fault may lead to an error, i.e., an error is a mechanism by which the fault becomes apparent. A fault may stay dormant for a long time before it manifests itself as an error. A fault that does not lead to an error is considered a latent fault. A fault that leads to an error is an active fault.
Examples:
- A memory bit cell became stuck but the CPU does not access the data stored in this cell (fault, no error). Once this bit is accessed, incorrect data will be delivered (fault, error).
- A software "bug" in a subroutine is not "visible" while the subroutine is not called (fault, no error). Once the subroutine is called, the fault will lead to an error.

Figure 7: Software bug
Source: HIMA Paul Hildebrandt GmbH
An input of an OR-gate is shortened to ‘0’. As long as at least one of the other inputs is set to ‘1’ this fault will never cause an error since the output of the gate will be ‘1’, independent from the shortened input (fault, no error). If none of the other inputs is set to ‘1’ and the faulty input was supposed to be set to ‘1’, the generated output will be wrongly set to ‘0’ (fault, error).

Figure 8: Example of Faults and Errors
Source: HIMA Paul Hildebrandt GmbH

Figure 9: Memory bit stuck at 0
Source: HIMA Paul Hildebrandt GmbH
- A circuit controls an alarm optical signal. A lamp should turn red when the output is ‘1’ and green when it is ‘0’. A hardware fault leads to a shortened output signal to ‘0’. As long as the lamp should be off, no failure will occur. If the lamp should turn red due to some requirements, then a failure will occur.
A failure is a non-performance of some action that is due or expected. A failure occurs when a system does not perform its required function. The presence of an error might cause an entire system to deviate from its required operation. One of the essential goals of safety-critical systems is that errors should not result in system failure.
Examples:
- A memory bit stuck at ‘0’ (fault) could lead to a wrong temperature value (error). If it is outside a specified range, a safety function could be affected (failure).
1.3 Important relations
Faults, errors, and failures operate according to a chain mechanism. This mechanism is sometimes known as a Fault-Error-Failure chain. As a rule, a fault, when activated, can lead to an error. The invalid state generated by an error may lead to another error or a failure (which is an observable deviation from the specified behavior at the system boundary). It is important to note that failures are recorded at the system boundary. They are basically errors that have propagated to the system boundary and have become observable.
Thus, a fault can lead to an error. An error can lead to a failure. A failure in a component can lead to a fault in an element etc.

Figure 10: Fault-Error-Failure blockchain
Source: HIMA Paul Hildebrandt GmbH
Example:
A bug in a software program is a fault. Possible incorrect values caused by this bug are errors. A possible blue screen due to a crash of the operating system is a system failure.

Figure 11: Bug in a software program
Source: HIMA Paul Hildebrandt GmbH
Note:
Considering the subdivision of systems into subsystems, elements, and components, a failure at a lower level can lead to a fault at the next level. For instance, if we consider a sensor as an element of a safety system a fault in this element can cause an error that can lead to failure on the element level. At system level, this failure might be a latent fault that does not lead to an error, etc.
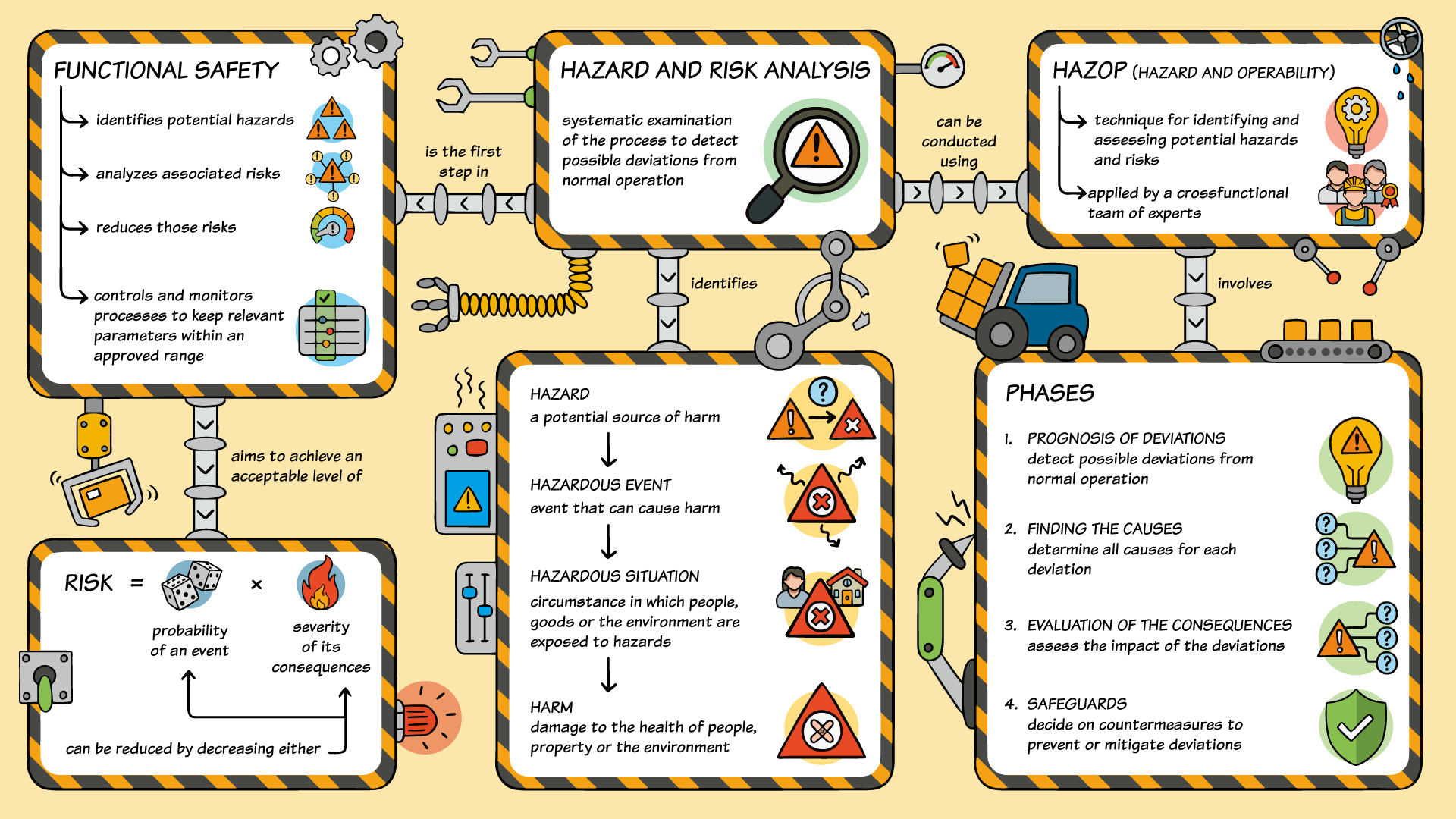
2 Classifications
As the concept of faults, errors, and failures is controversial, the classic method is to classify these terms according to various criteria. While certain classifications are dedicated to faults, others are better suited to failures. For other behaviors, a classification according to errors is more common. In the following, an overview of common classifications is given. In this context, it is especially important to mention that these classifications are also used for other terms.
Typically, it is important to take a look at the origin of faults before discussing the various classifications.
Possible origins of faults are:
- Incorrectly specified requirements
- Implementation mistakes
- Misunderstanding requirements
- Poor design and implementation
- Component defects
- Wearing out and aging
- Manufacturing faults
- External effects
- Radiation
- Operator mistakes
If we take a deeper look into the origins of faults, we can find out various categories to classify faults. In the following, a set of possible classifications is given. Afterward, the most important classifications for the evaluation of safety-related systems are described in detail. Finally, the classifications related to the standard IEC 61508 are introduced.
Possible categories to classify faults in are:
- Domain: hardware, software, and human faults
- Nature: systematic and random faults
- System boundaries: internal and external faults
- Duration: transient and permanent faults
- Dependency: dependent and independent faults
2.1 Software, hardware and human faults
The first classification is based on the domain of the faults.
Accordingly, faults can be at the hardware level, software level, or human level. While hardware faults are directly related to physical defects, software faults are mainly coding mistakes that may lead to a situation in which a correct hardware fails. In the case of faultless hardware and software, a human fault such as an operating fault can lead to a faulty system.

Figure 12: Classification based on the domain
Source: HIMA Paul Hildebrandt GmbH
2.2 Systematic and random
The second criteria is the nature of the origin of faults. Faults can be generated in a systematic or a random way. Systematic faults are mainly related to a process or to methods. It is any fault in the way of applying methods or processes whose consequent failure shows up in a deterministic way. This consequent failure is what is called a systematic failure.
Deterministic means here that this fault is going to cause the same behavior in every system. If the same fault is injected into the system 'n' number of times under specific conditions, the same failure will occur every time.
Systematic faults may include many diverse types of faults. Specification and design mistakes, manufacturing defects, or poor operation and maintenance behavior are the most commonly known types. Thus, systematic faults can be related to hardware and software.
- One example of a systematic hardware fault is a missing route in the PCB layout between a microcontroller output port and an LED port. This fault always leads to not being able to turn on the LED.
- One example of a systematic software fault is a coding bug in which an assignment operator (=) is used instead of an “equal to” operator (==). In this case, an output signal cannot be turned ON when requested because the system will falsely evaluate the condition.
Random faults are typically physical faults related to hardware. Random faults are caused by spontaneously occurring, unpredictable processes or mechanisms during the runtime of a system. Random faults occur randomly in time and are usually brought on by excessive stress on the system. Stress factors can have different causes. The consequent failure is called a random failure.
In contrast to systematic failures, random failures "just happen" in a way that is not deterministic and not related to any obvious problem or mistake. So even in a "correct" design, with no obvious flaws or oversights, we must account for the possibility of a random failure.
Typical examples of random faults are the following, based on aging or the stress failure of electronic components:
- Contact failure
- Soldered joint failure
- PCB/semi-conductor failure
- Relay stiction
- Resistor/capacitor degradation

Figure 12: Software and hardware faults: Systematic vs random
Source: HIMA Paul Hildebrandt GmbH
2.3 Transient and permanent
Another criterion for classifying faults is the duration of the faulty behavior. Here, different types are distinguished: permanent, transient, and intermittent faults.
Permanent faults are faults with an infinite duration. They are persistent and exist until the faulty component is corrected, removed, or repaired. Examples of permanent faults are broken transistors, missing routes, or software bugs. Permanent faults lead to hard errors.
Transient faults are faults of finite duration. They occur for a certain time and then disappear. A typical example of a transient fault is a radiation-based upset that causes a temporary change in the content of a memory cell. Usually, this fault disappears after the memory cell is refreshed. Transient faults lead to soft errors.
Intermittent faults are faults with an irregular duration. They occur at intervals, usually irregularly, in a system that functions normally at other times. Typical examples of intermittent faults are faults caused by surface corrosion (e.g., oxidation of pins or fretting wear), bent pins, debris within the female connector, or incorrect installation during initial manufacture and assembly.
Figure 14: Permanent, transient, intermittent faults
Source: HIMA Paul Hildebrandt GmbH
2.4 Dependent and independent
Faults can be distinguished by their dependency on other faults. An independent failure is caused by a fault in a system component that does not affect any other component in the system. By contrast, a dependent failure is a failure that is in some way related to or dependent on another failure.
Dependent failures are also known by terms such as "common mode failure", "common cause failure" or "cascading failures".
2.5 IEC 61508 classification

Figure 14: Failure classification based on the IEC 61508 standard
Source: HIMA Paul Hildebrandt GmbH
From a Functional Safety point of view, failures are the most important term to be considered. In this context, the standard IEC 61508 mainly deals with the classification of failures (Figure 15). The classifications are made according to:
- Causes: random and Systematic failures
- Effects: safe and dangerous
- Detectability: detected and undetected
While random and systematic failures result from random and systematic faults, both represent safe or dangerous failed behavior. A safe failure can result in a loss of a function that is not related to the safety of the system. However, a dangerous failure may result in a malfunction which leads to a loss of safety.
IEC 61508 defines safe failures as follows:
Failure of an element and/or subsystem and/or system that plays a role in implementing the safety function which:
- determines the spurious operation of the safety function to bring the EUC (or part of it) into a safe state or maintain a safe state,
- increases the likelihood that the spurious operation of the safety function will bring the EUC (or part of it) into a safe state.
Safe failures usually result in a loss of production of services but not a loss of safety. On the other hand, the IEC 61508 defines dangerous failures as follows:
Failure of an element and/or subsystem and/or system that plays a role in implementing the safety function that:
- prevents the operation of a safety function when required (demand mode) or causes the failure of a safety function (continuous mode) so that the EUC is put into a dangerous or potentially dangerous state,
- decreases the probability that the safety function functions correctly when required.
If not detected soon enough, dangerous failures may lead to a loss of safety.
Safe failures and dangerous failures can be detected and undetected. ISO TR 12489 delivers the following definitions of detected and undetected failures, which match the standard IEC 61508. Accordingly, a detected failure is immediately evident to operation and maintenance personnel as soon it occurs. Typical examples are failures reported as diagnostic faults. An undetected failure is not immediately evident to operation and maintenance personnel. A typical example is a failure that is still hidden until the component is asked to conduct its function.
The classification of detected and undetected failures is used with the classification of safe failures and dangerous failures to create four important failure categories:
- Safe detected failures
- Safe undetected failures
- Dangerous detected failures
- Dangerous undetected failures

Figure 16: Failure categories based on IEC 61508
Source: HIMA Paul Hildebrandt GmbH
3 Means of dependability

Figure 16: Means of dependability
Source: HIMA Paul Hildebrandt GmbH
3.1 Fault prevention
This solution aims to prevent the occurrence or introduction of faults. It is a proactive strategy to identify all potential areas where a fault can occur and to close those gaps. During the requirements phase, the concept and requirements that are incomplete or ambiguous will cause many defects during development.
Prevention of faults is based on the rigor in the development process. The rigor of the development process requires the establishment of an independent quality assurance process, which is essential in the development of dependable systems.
3.2 Fault removal
This solution aims to reduce the number and severity of faults by detecting them. This can be achieved through various verification and validation techniques, which includes devising comprehensive test cases, continuous integration and testing, cross-verification using a traceability matrix, automated testing, and so on. Continuous and iterative integration and testing is an effective way to catch faults early on. Review and walkthrough methods also help in the early detection of faults.
3.3 Fault tolerance
In this solution, the goal is to live with existing faults, tolerate them, and avoid failures in the presence of these faults. In order to avoid interrupting the operation of a given system, it is important to carry out mechanisms that will allow the system to continue delivering the required service even in the presence of active faults.
Fault tolerance refers to the ability of a system to continue operating without interruption when one or more of its parts fail. Fault tolerance is usually achieved by using some form of redundancy in the system.
3.4 Fault forcasting
This solution strives to estimate the present number, the future incidence, and the likely consequences of faults. A set of methods is applied to estimate the present number of faults, their future incidence, and the likely frequencies of their future occurrences. It aims at removing the effects of faults before their occurrences and can be considered as a subset of fault removal.
Conclusion
This paper showed how to interpret the terms fault, error, and failure. A fault is defined as a defect in a system that leads to an inability to perform a required operation. An error is a discrepancy between a calculated or measured value caused by a fault. A failure is always associated with a loss of function conforming to a given set of requirements.
Furthermore, this paper gave an overview of the different classifications of faults, errors and failures. Special attention was focused on the classification of failures in accordance with the standard IEC 61508, which is essential for the evaluation of safety systems. Finally, it introduced a set of methods that can be applied to enhance the dependability properties of a system.
Sources
List of references
[1] "IEC 60050 - International Electrotechnical Vocabulary - Welcome," IEC - International Electrotechnical Commission. https://www.electropedia.org/
[2] Avižienis, J.-C. Laprie, and B. Randell, “Fundamental concepts of dependability,” Department of Computing Science Technical Report Series, Jan. 2001, [Online]. Available: https://eprints.ncl.ac.uk/file_store/production/55707/35D90208-2D34-4C19-BFB5-65E037791AE6.pdf
[3] M. Rausand, Reliability of Safety-Critical Systems: Theory and Applications. 2014. [Online]. Available: https://www.amazon.com/Reliability-Safety-Critical-Systems-Theory-Applications/dp/1118112725
List of standards
[4] Functional safety of electrical/electronic/programmable electronic safety-related systems - Part 4: Definitions and abbreviations, IEC 61508-4:2010.
[5] Information technology — Vocabulary, ISO/IEC 2382.
[6] Petroleum, petrochemical and natural gas industries — Reliability modelling and calculation of safety systems, ISO/TR12489:2013.